目录
背景介绍
自2017年Transformer架构提出以来,大规模语言模型(LLMs)取得了飞速发展,并在语言理解、文本生成与逻辑推理等领域展现出突破性成果。然而,这一进步的背后始终伴随着沉重的代价——极高的计算与资源开销。传统Transformer模型,尤其是其核心的自注意力机制,计算复杂度和内存占用随输入序列长度呈平方级增长。这一特性使得模型在处理长文档、源代码或多轮对话等场景时,计算需求急剧膨胀,训练成本高昂,推理部署亦面临巨大挑战。当下的智能时代,正逐渐被高昂的计算成本所塑造。
为了突破这一”效率瓶颈”,全球研究者们持续探索并付出了巨大努力。本文将基于综述论文 Speed Always Wins: A Survey on Efficient Architectures for Large Language Models,系统梳理人工智能社区在提升大模型效率方面所提出的多样化技术路径。这篇综述不仅为我们勾勒出现代高效LLM架构的全景蓝图,也揭示了通往”高效智能”的道路并非单一,而是充满多元化与创新性的可能。

1. LLM面临的核心挑战
大型语言模型(LLM)的卓越能力,源自于其庞大的参数规模以及在海量数据上的训练。然而,这种依赖规模驱动的范式也带来了若干亟待解决的核心挑战:
-
训练成本:训练一个千亿参数级别的模型,往往需要数千张顶级 GPU 持续运行数月,其资金投入与能源消耗均达到天文数字级别。
-
推理延迟:在真实应用场景中,用户无法容忍数十秒的响应延迟。然而,自注意力机制在长序列输入下的高复杂度,极易导致推理速度骤降。
-
内存瓶颈:推理过程中,模型需存储历史 Token 的 Key 与 Value(KV Cache)。随着输入序列的增长,KV Cache 会迅速消耗完显存,从而严苛地限制了上下文处理能力。
-
部署门槛:对高性能硬件的依赖,使得前沿模型难以在常规设备乃至边缘设备上运行,严重制约了其普及与落地。
综上所述,模型架构的效率优化已不再是”锦上添花”,而是决定 LLM 技术能否持续演进与大规模应用的关键”生死线”。本文旨在对此领域的最新进展进行系统性梳理,并对近年来的创新方法进行分类总结,以期勾勒出研究全貌。
2. 效率革命的主要方向
在《Speed Always Wins》综述中,高效 LLM 架构的研究被系统性地归纳为七大方向。每一类方法都代表了一条独立的研究路径,共同构成了理解该领域的核心框架:
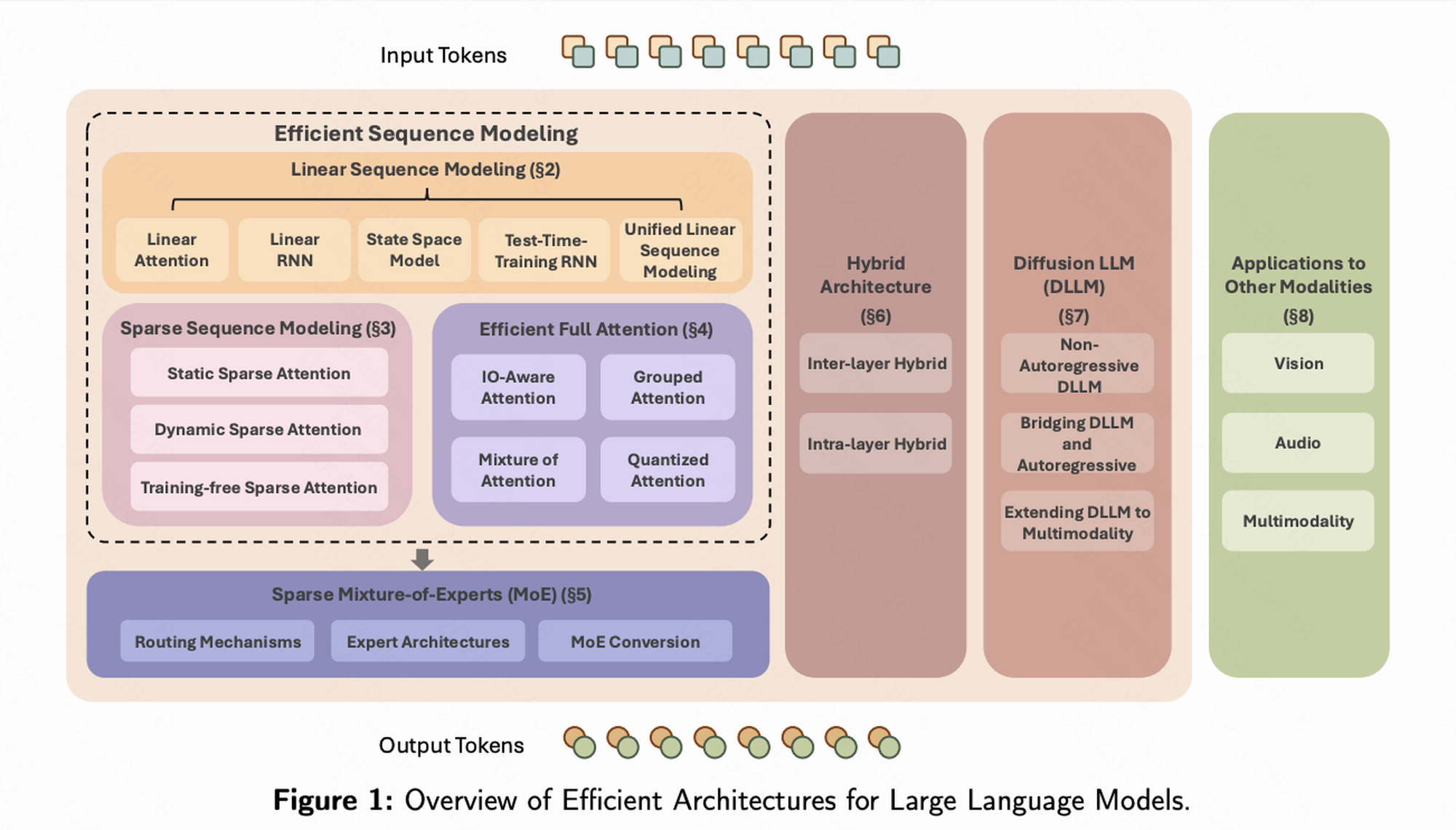
-
线性序列建模(Linear Sequence Modeling)
作为最”激进”的范式革新,其目标是将注意力机制的复杂度由二次方直接降至线性,从根本上解决长序列扩展性问题。 -
稀疏序列建模(Sparse Sequence Modeling)
代表了强调实用性的”抓重点”策略。其核心思想是:并非每个 Token 都需要全局依赖,而是通过选择性地聚焦于少量关键 Token 来显著降低计算量。 -
高效全注意力(Efficient Full Attention)
属于对现有机制的”优化升级”。其保留了原始自注意力的数学框架,但通过底层算子优化与硬件加速,显著提升了计算效率。 -
稀疏专家混合(Sparse Mixture-of-Experts, MoE)
体现了”人多力量大”的思路。该方法构建超大规模参数空间,但在推理时仅激活少量专家模块,从而在不显著增加计算开销的情况下扩展模型容量。 -
混合架构(Hybrid Architectures)
强调”融合与权衡”。其将多种机制(如线性注意力与全注意力)进行组合,旨在兼顾效率与性能,寻求最优平衡点。 -
扩散大模型(Diffusion LLMs)
属于”范式颠覆”的探索。它们跳脱出传统的自回归生成模式,转而采用并行化的扩散生成方式,从而显著提升推理速度。 -
跨模态应用(Applications to Other Modalities)
展现了方法的”普适性与外延”。这些技术思路已被成功应用于视觉、语音等其他模态任务,推动了跨模态大模型的高效化发展。
接下来,我们将逐一剖析上述方向的核心技术原理及代表性工作,以勾勒该领域的研究全貌。
2.1 线性序列建模

传统自注意力(Self-Attention)的计算可以简化为:
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^{\top}}{\sqrt{d_k}}\right) V\]其中,计算 $QK^{\top}$ 会生成一个 $N \times N$ 的注意力矩阵($N$ 为序列长度),因此整体计算复杂度为 $O(N^2d)$。
线性注意力(Linear Attention) 的核心思想是:将 softmax 操作替换为一个可分解的”核函数”表示,即将相似度函数表示为
其中 $\phi(\cdot)$ 是一种核映射函数。这样一来,计算可利用矩阵乘法的结合律重排为:
\[\text{Output} = \big(\phi(Q)\phi(K)^{\top}\big) V = \phi(Q)\big(\phi(K)^{\top}V\big)\]在此重排下,$\phi(K)^{\top}V$ 的维度仅为 $d \times d$($d$ 为特征维度),与序列长度 $N$ 无关。由此,整体计算复杂度从原始的
\[O(N^2 d) \;\;\; \longrightarrow \;\;\; O(N d^2)\]当 $N \gg d$ 时,优化效果尤为显著。
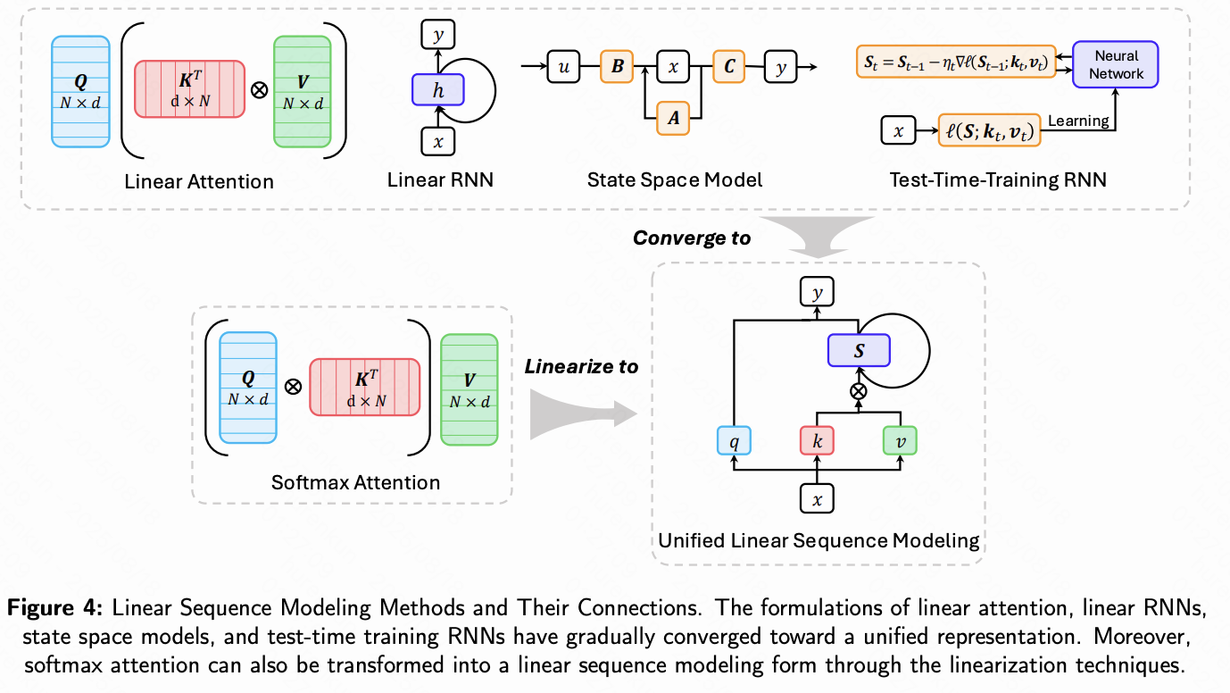
线性序列建模的两大主要分支
在统一的理论框架下,线性序列建模逐渐分化出几个重要方向,其中最具代表性的是 线性 RNN 与 状态空间模型(SSM)。
- ** 线性 RNN(Linear RNNs)**
线性 RNN 在结构上与传统循环神经网络(RNN)相似,但移除了非线性激活函数,使得其转化为可并行计算的线性系统,从而显著提升推理效率。
这类模型既保留了 RNN 在长序列处理中的结构优势,又通过线性化设计保持了较低的计算复杂度。
其中 RWKV 模型是代表性工作,它巧妙地在 RNN 框架中融入 Transformer 式的设计,兼顾了高效性与强大建模能力。
- ** 状态空间模型(State Space Models, SSMs)** SSM 源于控制理论,其核心思想是将输入序列视为连续信号,并通过一个”状态变量”进行历史信息建模,根据当前输入动态更新状态并产生输出。其基本形式为:
早期的 SSM 已经展现出极强的长序列建模能力,而真正推动该方向快速发展的,是 Mamba 模型 的提出。
Mamba 的核心创新在于 选择性机制(Selection):模型通过动态调整状态转移矩阵,依据输入灵活决定”记忆”或”遗忘”哪些信息。
这一机制赋予模型更强的上下文感知与信息选择能力,使其在性能上能够媲美顶级 Transformer 模型,同时仍保持线性复杂度。
小结
线性序列建模不仅具有极高的计算效率,更代表了序列建模的一种革命性路径。
它们试图从根本上重塑序列建模范式,而 Mamba 的成功 标志着这一方向已从理论探索迈向实际应用。
2.2 稀疏序列建模:精打细算,聚焦重点
稀疏序列建模的核心思想十分直观:全局注意力的计算代价高昂,且往往并非必要。只需在关键位置施加注意力,就能够以更低的成本捕捉核心依赖关系。

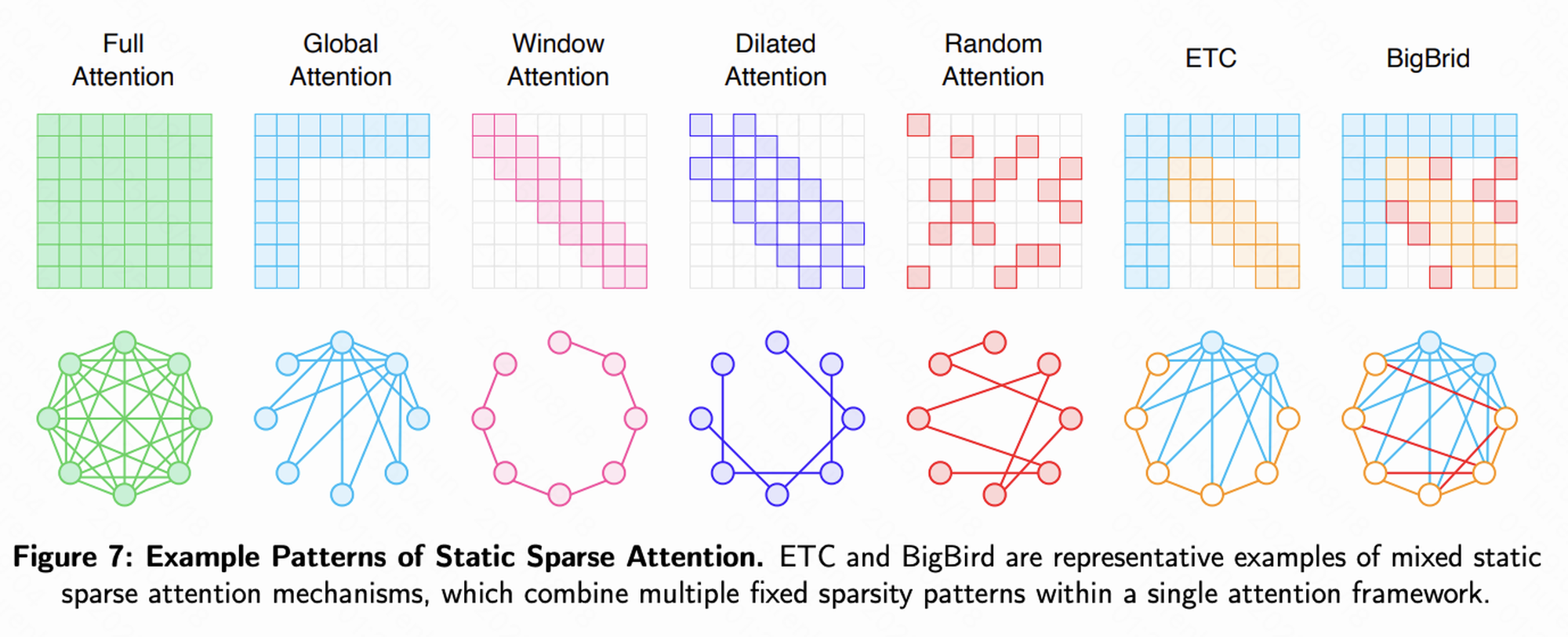
1. 静态稀疏注意力(Static Sparse Attention)
在训练前预先设定固定的注意力模式,代表性方法包括:
- 滑动窗口注意力(Sliding Window):每个 Token 仅关注其邻近的若干 Token,适合建模局部依赖性强的任务。
- 全局注意力(Global Attention):少量特殊 Token(如
[CLS])能够访问全局信息,其余 Token 仍采用局部注意力。 - 组合模式:如 Longformer 和 BigBird,通过融合滑动窗口、扩张滑动窗口(Dilated)以及全局注意力,确保任意两个 Token 间存在较短的信息路径,在近似全注意力表达力的同时,实现了线性复杂度。
类比:这类似于一个社交网络——大多数人主要与身边的朋友交流(滑动窗口),但也会关注少数”意见领袖”的动态(全局 Token)。
2. 动态稀疏注意力(Dynamic Sparse Attention)
相较于静态方法,动态稀疏注意力的模式会根据输入内容自适应生成。
例如,模型可通过聚类将相似的 Token 划分为一组,并仅在组内进行注意力计算,从而在保持效率的同时增强建模灵活性。
3. 训练无关稀疏化(Training-free Sparse Attention)
该类方法专注于推理加速,无需重新训练。
一个典型案例是 StreamingLLM 提出的 注意力沉降(Attention Sink) 现象:
即便在超长序列中,模型仍会持续给予开头几个 Token 极高的注意力权重。
据此,只需在 KV Cache 中保留这些”沉降” Token 及最近一个滑动窗口,即可在几乎不损失性能的前提下,实现对无限长序列的推理。
小结
稀疏序列建模通过”去冗余”的策略,在保留关键依赖的同时显著降低计算复杂度。
无论是 固定模式、动态生成,还是 推理时稀疏化,这些方法都为长序列建模提供了高效可行的解决方案。
2.3 高效全注意力:压榨硬件的每一滴性能

高效全注意力(Efficient Full Attention)的方法可谓是”戴着镣铐跳舞”的典范。
它们不改变注意力机制的数学形式,而是通过底层计算与内存访问优化,最大限度挖掘硬件潜能。最具代表性的成果便是 FlashAttention。
1. FlashAttention
FlashAttention 的核心在于充分利用 GPU 的分层存储结构:
- SRAM(片上缓存):速度极快,但容量有限。
- HBM(高带宽显存):容量大,但读写延迟显著。
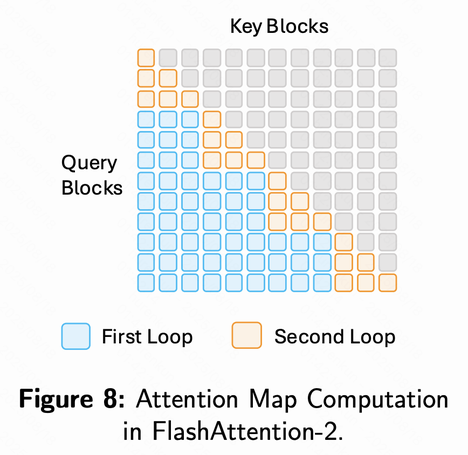
传统注意力的瓶颈在于:计算过程中需频繁读写庞大的注意力矩阵到 HBM,导致大量时间消耗在内存访问上。
FlashAttention 的优化思路类似于一位高效厨师:
- 标准实现:每切好一种菜(计算一个中间结果),就放回远处的冰箱(HBM),需要时再取出。
- FlashAttention:提前把做菜需要的食材(数据块)搬到手边的操作台(SRAM),在操作台完成所有步骤(Tiling & Fused Kernels),最终产出成品后再写回冰箱。
这种 IO-aware 设计 使得 FlashAttention:
- 将内存访问量显著降低;
- 在完全保真(无近似)的前提下,实现 2–4 倍加速;
- 同时大幅减少显存占用。
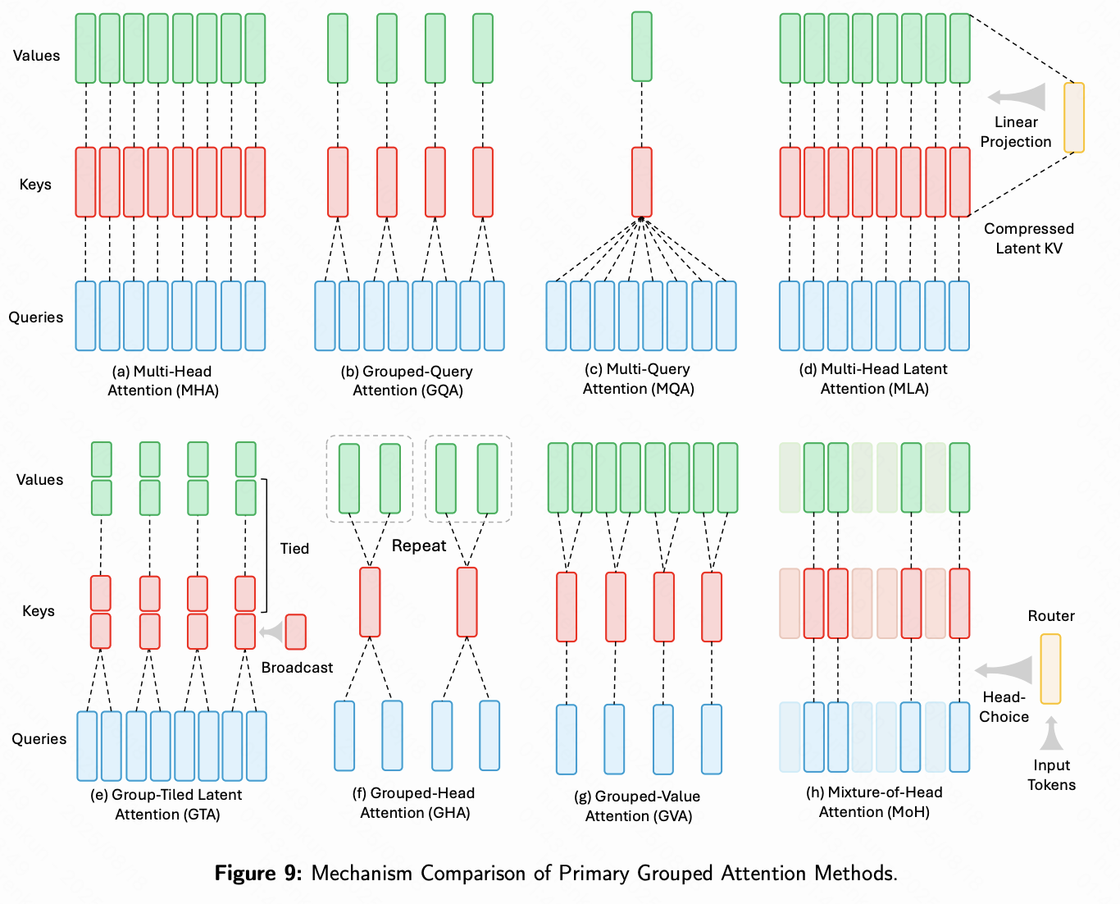
2. 分组查询注意力(Grouped-Query Attention, GQA)
另一类高效化思路是 减少 KV Cache 开销:
在多头注意力机制中,通常每个查询头(Query Head)都对应独立的键值头(Key/Value Heads)。
GQA 则允许 一组查询头共享同一对键值头,从而:
- 显著减少推理时 KV Cache 的存储需求;
- 在几乎不损害性能的情况下,提升推理吞吐量。
总结
高效全注意力,尤其是 FlashAttention,已成为训练与部署 SOTA LLM 的事实标准。
它清晰地证明:通过 软硬件协同优化,无需牺牲模型表达能力,也能大幅释放计算与存储效率潜力。
2.4 稀疏专家混合(MoE):参数高效扩展的分工机制

稀疏专家混合(Mixture of Experts, MoE)是一种与传统方法正交的、用于大规模扩展模型能力的高效技术。其核心思想是:通过增加模型参数总量提升模型容量,但在每次计算中仅激活其中一小部分参数,从而保持计算成本可控。
MoE层结构
一个典型的MoE层主要包含两部分:
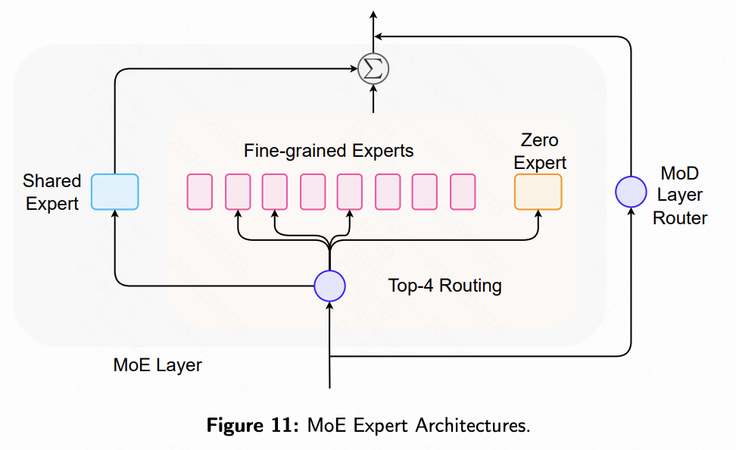
- 专家网络(Experts):每个专家通常为一个独立的前馈网络(Feed-Forward Network, FFN),负责特定输入的处理。
- 门控网络(Gating Network)或路由器(Router):根据每个输入Token的特征,决定由哪些专家进行处理。
工作流程
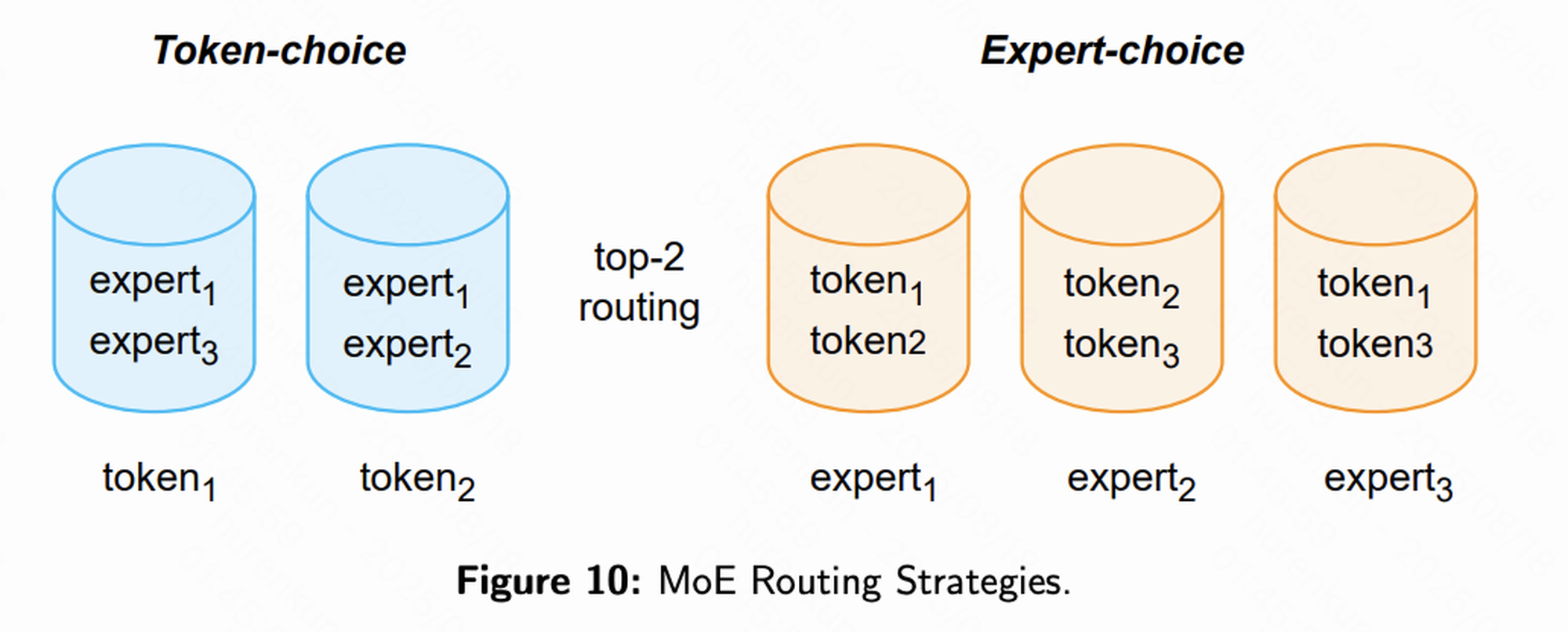
当输入Token序列进入MoE层时:
- 路由器为每个Token计算概率分布。
- 选择得分最高的Top-k个专家(通常k=2)。
- Token仅送入这k个专家进行处理,最终输出为各专家输出的加权和。
类比示例:
想象一个大型咨询公司,拥有数千名不同领域的专家(法律、金融、技术等)。当客户提出问题时,前台(路由器)快速判断问题所属领域,并只将客户引荐给最相关的两位专家。这样,公司虽然规模庞大,但解决单个问题的成本仍然低廉。
核心挑战与解决方案
MoE的主要挑战之一是负载均衡(Load Balancing):
- 如果路由器偏向某些”明星专家”,其他专家可能长期未被激活,导致训练不充分,同时”明星专家”成为性能瓶颈。
- 解决策略:引入辅助损失函数,对路由分配进行惩罚,鼓励任务均匀分布至所有专家。

代表模型
- Mixtral 8×7B:典型的MoE模型,包含8个专家,每次激活2个。其激活参数量约为14B,性能可媲美70B级别的密集模型。
总结
MoE为构建万亿参数模型提供了高效路径。通过解耦模型总参数量与单次前向计算量,它让模型的”知识容量”得以在前所未有的规模下扩展,同时保持可控的计算成本。
2.5 混合架构——强强联合,取长补短

不同模型方法各有优势与局限,因此将多种方法有机结合,发挥各自长处,成为提升性能与效率的自然选择。
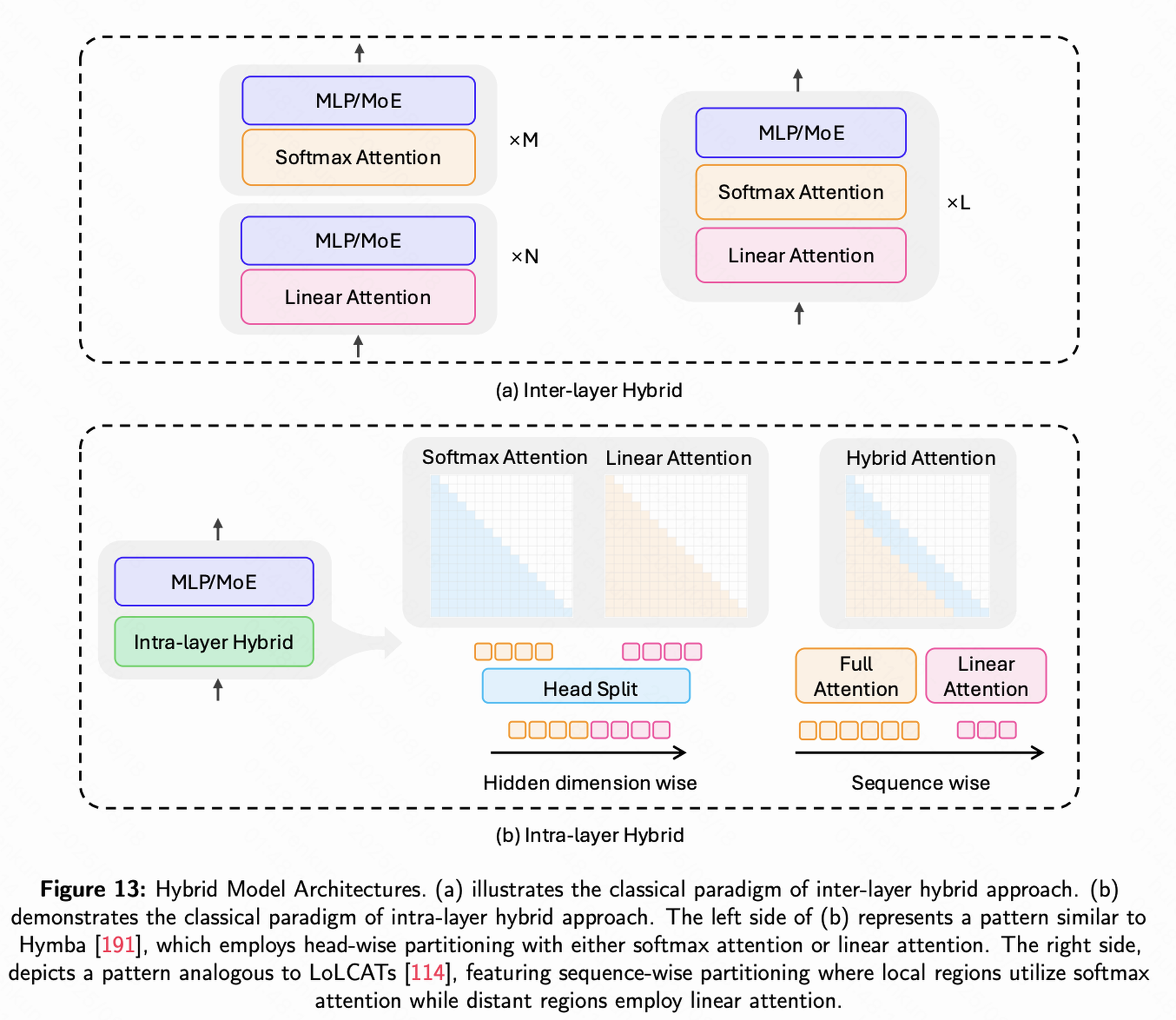
层间混合(Inter-layer Hybrid)
- 定义:在模型的不同层采用不同类型的模块。
- 策略:大多数层使用高效的Mamba模块,而在少数关键层插入功能更强的全注意力(Full-Attention)模块。
- 优势:在保证整体计算效率的同时,利用全注意力层捕捉并整合全局信息。
- 典型案例:Jamba模型,通过交错堆叠Mamba和Transformer层,并结合MoE机制,实现性能与效率的高度平衡。
层内混合(Intra-layer Hybrid)
- 定义:在同一注意力层内混合不同的计算机制。
- 策略:不同注意力头采用不同策略,例如部分头执行局部注意力,另一部分头处理全局或稀疏注意力。
- 优势:在单层内实现多尺度信息捕捉,提高表达能力与灵活性。
总结
混合架构是当前务实且前沿的设计范式。它承认单一架构无法兼顾所有需求,通过层间与层内的灵活组合,可以实现针对特定任务的最优效率—性能权衡曲线。
2.6 扩散大模型(Diffusion LLMs)——并行生成的新范式

扩散大模型代表了一种与传统自回归LLM截然不同的生成哲学。
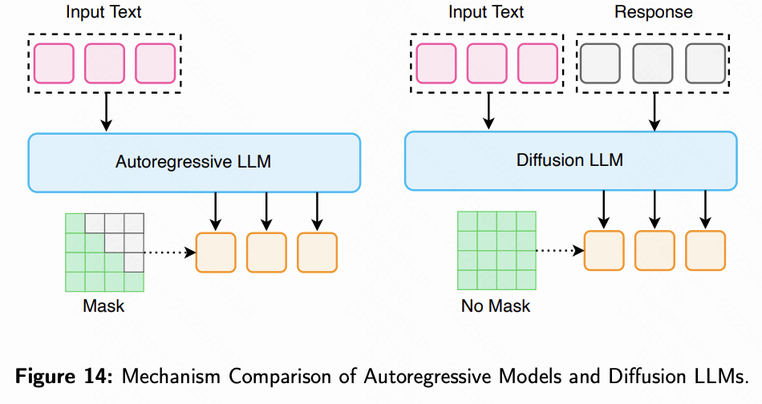
自回归模型(Autoregressive Models)
- 生成方式:逐步生成,每次输出一个Token。
- 优点:连贯性强,生成文本结构自然。
- 缺点:推理速度受限,生成第N个Token需等待前N-1个Token完成。
扩散模型(Diffusion Models)
- 生成方式:从完整的随机噪声开始,通过多步”去噪”逐步形成最终文本,相当于一次性生成整句或整段内容。
- 类比:像雕塑家从原材料雕琢出作品,而非作家逐字书写。
核心优势
- 并行解码:所有Token可同时生成,推理延迟显著低于自回归模型,适用于对实时性要求高的场景。
- 可控性强:扩散过程天然支持对输出内容进行约束,可控制文本长度、格式或风格。
发展现状
- 在图像生成领域,扩散模型已展现出卓越性能。
- 在文本生成方面,虽然传统扩散LLM略逊于顶级自回归模型,但随着 LLaDA 等新一代模型的出现,这一差距正在快速缩小。
- 潜力巨大:扩散LLM若在性能上完全追平自回归模型,可能引发语言生成领域的新范式转移。
扩散大模型为高效、可控的文本生成提供了一条全新路径,正推动生成式AI迈向更低延迟与更高灵活性的未来。
3. 展望未来 LLM 高效架构
本文综述最后提出了未来大型语言模型(LLM)高效架构的几个关键研究方向:
3.1 软硬件协同设计
未来的模型架构将不仅依赖算法创新,还需实现 算法、系统与硬件的深度协同设计。
- 目标:在保证模型能力的同时,最大化计算效率和能耗优化。
- 意义:单纯依赖算法优化已难以充分发挥现代硬件潜力,协同设计是提升整体性能的必然趋势。
3.2 动态与自适应计算
模型将更加智能,能够根据输入复杂度与可用资源 动态调整计算策略:
- 示例:动态选择激活的专家数量、调整稀疏度或层级计算路径。
- 优势:在保证精度的前提下,实现更高的计算效率和实时响应能力。
3.3 超越文本的高效建模
高效架构设计的理念将扩展到 多模态和复杂数据处理:
- 应用场景:高分辨率视频理解、基因序列建模、3D场景解析等。
- 目标:在处理长序列或高维复杂数据时,保持性能和效率的最优平衡。
这些研究方向表明,未来 LLM 的发展将不仅关注模型规模,更关注 可扩展性、智能调度与跨模态能力,推动高效生成与理解能力进入新阶段。
4. 总结与展望
当前,我们正处于大型语言模型(LLM)架构”百花齐放”的黄金时期。曾经由 Transformer 占据主导的格局,正在被多样化、高效化的新型架构所重塑。
未来的大模型将不再是单一的庞然大物,而是由 多种高效组件灵活组合而成的智能系统。正如综述标题所强调的:”效率必胜(Speed Always Wins)”。在迈向通用人工智能(AGI)的长期征程中,能够在计算效率与性能之间取得最佳平衡的架构,将占据更加广阔的发展前景。
5. 参考文献
Review Papers
-
Speed Always Wins: A Survey on Efficient Architectures for Large Language Models
arXiv:2508.09834 -
A Survey of Large Language Models
arXiv:2303.18223
Linear Sequence Modeling
-
Log-Linear Attention
arXiv:2506.04761 -
ReGLA: Refining Gated Linear Attention
arXiv:2502.01578 -
RWKV-7 “Goose” with Expressive Dynamic State Evolution
arXiv:2503.14456 -
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
arXiv:2312.00752
Sparse Sequence Modeling
-
LongNet: Scaling Transformers to 1,000,000,000 Tokens
arXiv:2307.02486 -
Mixture of Sparse Attention: Content-Based Learnable Sparse Attention via Expert-Choice Routing
arXiv:2505.00315
Efficient Full Attention
-
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
arXiv:2205.14135 -
SageAttention 3: Microscaling FP4 Attention for Inference and an Exploration of 8-Bit Training
arXiv:2308.07652
Sparse Mixture-of-Experts
-
LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin
arXiv:2308.07652 -
MoEfication: Transformer Feed-forward Layers are Mixtures of Experts
arXiv:2308.07652
Hybrid Architectures
-
Zamba: A Compact 7B SSM Hybrid Model
arXiv:2308.07652 -
LoLA: Low-Rank Linear Attention With Sparse Caching
arXiv:2308.07652
Diffusion Large Language Models
- Large Language Diffusion Models
arXiv:2308.07652